Polkadot v1.0: Sharding e sicurezza economica
(articolo originale: qui)
Di Rob Habermeier, fondatore di Polkadot
Questo post parla della tecnologia che alimenta Polkadot. Polkadot è una blockchain sharded con shard eterogenei. Il significato di sharding in questo contesto è la suddivisione del lavoro che avviene su più sotto-blockchain, note come parachain. Il significato di eterogeneo in questo contesto è che ogni blockchain ha la propria funzione di transizione di stato, costruita appositamente per un caso d'uso specifico. Diversi tipi di transazioni avranno case diverse, il che consente alle blockchain specializzate di servire i propri utenti nel modo più efficiente. Polkadot fornisce funzionalità di sicurezza e di messaggistica per tutte le parachain collegate.
Questo post è stato scritto principalmente per un pubblico tecnico con una certa conoscenza del consenso delle blockchain. Spero che si riveli utile anche per chi non è un pubblico di questo tipo e che fornisca una visione dei problemi e delle sfide che devono affrontare le blockchain del livello base e di come Polkadot affronta questi problemi. Non intendo esaminare tutte le sfumature delle nostre soluzioni, ma fornirò una descrizione approfondita dei tipi di cose che consideriamo e di come forniamo le garanzie che ci prefiggiamo.
Le chain (chain, inteso blockchain) prima della chain
Una comprensione semplificata della blockchain prevede una sola chain, che si estende dalla genesi alla testa della chain. Per molti, questo è l'unico concetto di chain che conta: rappresenta tutte le transizioni di stato che si sono verificate e che sono state concordate dalla rete. L'obiettivo finale di qualsiasi sistema di consenso blockchain è fornire agli osservatori questa fonte di verità. Tuttavia, questa singola chain, che possiamo chiamare chain finalizzata o chain canonica, è solo l'ultima sopravvissuta di molte possibili catene concorrenti che avrebbero potuto esistere. Il ruolo dell'algoritmo di consenso della blockchain è quello di iniziare con molte catene possibili e, alla fine, finalizzarne solo una.
Gli autori dei blocchi competono per il diritto di produrre il blocco successivo, ma ci può essere più di un vincitore alla volta. Nella proof of work, i miner si guadagnano il diritto di essere autori di un determinato blocco ( più o meno) trovando un modo per produrre un nuovo blocco che abbia come hashtag un numero casuale unico che sia inferiore a un obiettivo difficile da raggiungere. In un ambiente sufficientemente competitivo, può essere necessario un numero enorme di tentativi prima che un miner trovi un blocco che soddisfi questa condizione. Per esempio, l'hashrate cumulativo della rete Bitcoin al momento in cui scriviamo è di 162 Exahashes al secondo, il che significa che i miner Bitcoin in aggregato tentano 162 quintilioni di volte al secondo di guadagnarsi il diritto di contribuire al blocco successivo, e l'obiettivo di difficoltà è impostato in modo che in media solo un hash sarà al di sotto dell'obiettivo ogni 10 minuti. Si noti che è possibile che più miner trovino, più o meno contemporaneamente, una soluzione, il che introduce una piccola biforcazione nella blockchain. I futuri miner dovranno scegliere quale di questi blocchi minare, il che può causare l'allungamento della biforcazione. La regola è quella di seguire la chain più lunga, e diventa progressivamente più difficile per un attaccante che parte da un blocco passato raggiungere e sopraffare una chain più lunga. Per questo motivo, un blocco abbastanza profondo nella chain più lunga può essere considerato probabilisticamente definitivo.
La famiglia Ouroboros di protocolli proof-of-stake utilizza una tecnologia crittografica nota come Verifiable Random Functions (VRF) per simulare la proof of work dividendo il tempo in slot discreti e dando a ciascun validatore iscritto e registrato in un gruppo di validatori (l'insieme dei validatori) l'opportunità di produrre un valore casuale verificabile per slot di tempo che, se inferiore a una soglia, serve come credenziale per consentire al validatore di creare un nuovo blocco. Come nel caso della proof of work, più validatori possono produrre un valore con i loro VRF inferiore alla soglia e contemporaneamente scrivere blocchi, dando luogo a biforcazioni. I validatori sono disincentivati dall'introdurre biforcazioni intenzionali, cioè dall'utilizzare la loro credenziale per autorizzare più blocchi nello stesso slot, mediante una riduzione della loro quota sulla chain. Questi protocolli forniscono anche una finalità probabilistica in base alla regola della scelta della biforcazione più lunga della chain.
A differenza dei miner nel proof of work, i validatori in una rete di tipo Ouroboros devono eseguire un solo calcolo per avere la possibilità di creare un blocco, a differenza del numero assurdamente elevato di hash che i miner devono eseguire. Ciò consente ai validatori di dedicare la maggior parte del loro tempo alla creazione di un blocco con le transazioni e, di conseguenza, permette alla blockchain di contenere calcoli di maggior valore.
La relay chain di Polkadot (le catene trasferenti di Polkadot) utilizza un protocollo chiamato BABE, che è un'evoluzione di Ouroboros Praos. Il miglioramento specifico di BABE rispetto a Praos è che BABE evita di dipendere dai server NTP centralizzati per consentire ai validatori di conoscere l'ora corrente.

BABE è biforcato, con finalità probabilistiche
Sebbene la finalità probabilistica vada bene, aspettare che un blocco raggiunga una certa profondità nella chain più lunga è un meccanismo inefficiente, poiché è stato progettato per adattarsi al caso peggiore previsto, in cui la rete è sottoposta a un certo livello di tensione e di attacco. È possibile che la maggior parte della rete sia già d'accordo su quali blocchi facciano parte della chain canonica. In effetti, in quasi tutti i casi, la rete sarà in grado di concordare sul fatto che un blocco è canonico molto prima che raggiunga la profondità minima nella chain più lunga. Per questo motivo, introduciamo i concetti di gadget di finalità e di finalità assoluta. Un gadget di finalizzazione è un protocollo di consenso secondario che gira sopra una blockchain probabilisticamente definitiva e che dimostra un accordo più rapido su quali blocchi la rete considererà definitivi. Questi protocolli di consenso introducono un'ulteriore proprietà di sicurezza economica: il gadget di finalizzazione non finalizzerà mai 2 blocchi in competizione tra loro senza tagliare almeno 1/3+ della posta totale dell'insieme dei validatori.
La chain di Polkadot utilizza un dispositivo di finalizzazione noto come GRANDPA. È in grado di raggiungere una finalizzazione quasi istantanea su sotto-catene di qualsiasi lunghezza, e funziona approssimativamente facendo votare ripetutamente i validatori sui blocchi che percepiscono essere a capo della chain più lunga. GRANDPA funziona attualmente sulle reti Polkadot e Kusama è su Kusama, che al momento della stesura del presente documento conta 900 validatori, è in grado di ottenere la finalizzazione dei nuovi blocchi entro 3 secondi.
I validatori votano la chain che ritengono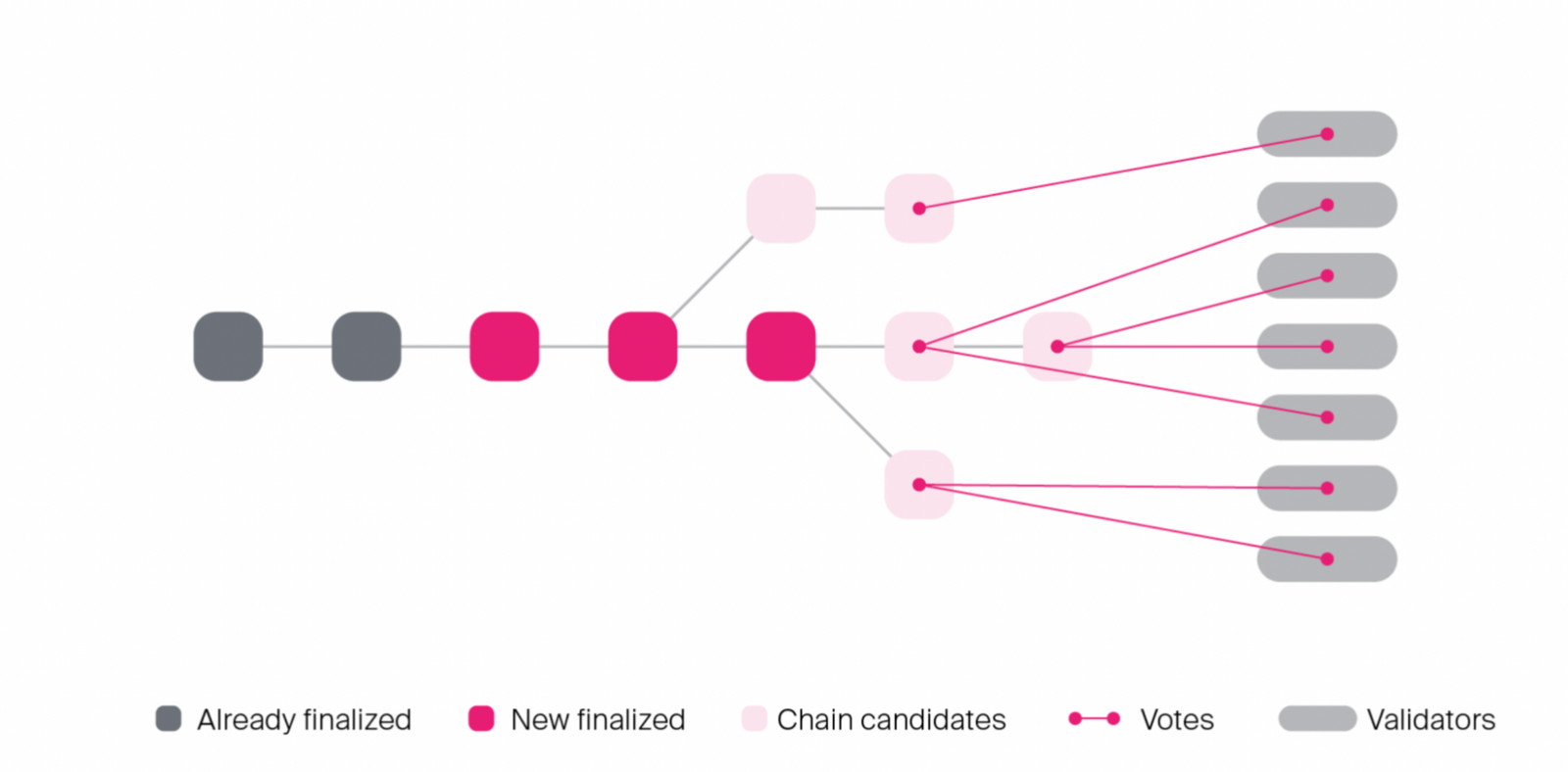
La combinazione di BABE e GRANDPA consente a Polkadot di far crescere in modo ottimizzato la chain con l'input di un solo validatore, il che è veloce, e di finalizzarla in background ottenendo il consenso di una supermaggioranza di validatori. Questa combinazione di proprietà fa sì che, in buone condizioni di rete, Polkadot raggiunga un alto rendimento e una bassa latenza, mentre in cattive condizioni di rete, la relay chain raggiunge un alto rendimento e un'alta latenza, poiché GRANDPA si riduce a seguire la finalità probabilistica di BABE.
Sharding: scalabilità tramite selezione di sottoinsiemi
Torniamo allo sharding. L'obiettivo dello sharding è quello di migliorare il throughput (flusso) suddividendo il lavoro, sotto forma di transazioni, su molte catene note come shard. Gli shard fanno riferimento e sono protetti da una blockchain di livello superiore. In Polkadot la blockchain di livello superiore è chiamata relay chain e gli shard sono parachain. La maggior parte dei dati che appaiono sulla relay chain sono transazioni che includono riferimenti a nuovi blocchi di parachain, il che rende economica l'elaborazione di qualsiasi fork della relay chain stessa. Si noti che qui faccio una distinzione tra i fork arbitrari della relay chain e la relay chain finalizzata. La maggior parte del nostro lavoro consiste nel garantire che la parte finalizzata della relay chain, che gli utenti vedranno come chain canonica, contenga solo riferimenti a blocchi di parachain validi.
Questo diagramma o altri simili sono ampiamente diffusi su Internet. Mostrano come i validatori vengono divisi in gruppi e assegnati alle Parachain e come ricevono le proposte di blocchi di Parachain dai collator. In questo post ho creato spiegazioni visuali di molti dei concetti più sfumati.

Lo sharding è un miglioramento della scalabilità solo se ogni validatore deve controllare solo alcuni dei blocchi della parachain inviati, anziché tutti. Se ci fossero 10 parachain e ogni validatore dovesse controllare tutti i blocchi di tutte e 10 le catene, tanto varrebbe mettere tutte le transazioni su un'unica blockchain e chiudere la questione. Il trucco consiste nel trovare un modo per far sì che ogni validatore svolga il minor lavoro di verifica possibile, pur mantenendo la sicurezza economica: i validatori che sostengono blocchi di parachain sbagliati sono economicamente disincentivati dal farlo. Più concretamente, dovrebbe essere impossibile per un gruppo avverso di validatori accordarsi per far includere un blocco di parachain difettoso nella relay chain finalizzata prima di perdere tutta la loro quota (le coin in staking) a causa dello slashing (taglio, ovvero perdita delle coin in staking). I validatori, in verità piccoli sottoinsiemi di validatori, possono accordarsi per ottenere blocchi di parachain difettosi referenziati da fork non finalizzati della relay chain, ma garantiamo che questi fork vengano ignorati prima della finalizzazione e che i colpevoli vengano sottoposti a slashing.
I blocchi parachain vengono finalizzati quando viene finalizzato un blocco sulla chain a relay che vi fa riferimento.

I blocchi parachain vengono finalizzati quando viene finalizzato un blocco sulla chain a relay che vi fa riferimento.
Stabiliamo alcune ipotesi concrete sull'avversario da cui ci difendiamo:
-
L'avversario può controllare fino a 1/3 di tutti i validatori e può controllare tutti questi validatori affinché si comportino esattamente come desiderato.
-
L'avversario può visualizzare tutti i messaggi di rete tra i validatori onesti e i validatori che controlla.
-
L'avversario può fare il DoS fino all'X% dei validatori in qualsiasi momento, impedendo loro di inviare o ricevere messaggi.
-
È necessario un ritardo fisso prima che l'avversario possa iniziare a fare DoS su qualsiasi validatore.
In questo post non presenterò una prova di sicurezza formale per il protocollo, ma questi vincoli dovrebbero fornire un'idea dei tipi di attacchi da cui intendiamo difenderci.
In realtà, la nostra unità di base per il consenso delle parachain non è una parachain, ma qualcosa che chiamiamo nucleo di disponibilità o core per abbreviare. Si tratta di qualcosa di simile ai core della CPU: operano in parallelo e hanno un lavoro programmato su di loro in intervalli di tempo discreti. Ogni parachain ha il suo core dedicato, il che significa che è sempre programmato su un particolare core. Tuttavia, possiamo anche moltiplicare più catene su un singolo core. L'unica differenza è l'algoritmo di schedulazione.
I core servono a descrivere efficacemente il rendimento della relay chain. I core corrispondono direttamente alla quantità di lavoro che i validatori devono svolgere. Ogni core può gestire fino a un blocco di parachain per ogni blocco della relay chain, al massimo.
In qualsiasi sistema di blockchain sharded, in cui solo alcuni validatori verificano ogni blocco di parachain, la disponibilità dei dati è una componente cruciale per assicurarsi che i dati necessari per verificare un blocco di parachain possano essere recuperati ai fini della rilevazione delle frodi. I core a disposizione sono gestiti dalla relay chain e tengono traccia di quali blocchi di parachain sono in attesa di disponibilità dei dati. Lo scopo principale dei core a disposizione è quello di essere come una primitiva di schedulazione e di fornire una backpressure quando la disponibilità dei dati è più lenta del solito.
La logica di un core a disposizione è la seguente. I core sono vuoti quando sono pronti ad accettare un nuovo blocco di parachain, a quel punto vengono occupati. Poi, i dati diventano disponibili o il processo di disponibilità va in time out. A quel punto, il core torna a essere vuoto.

È utile suddividere il consenso delle parachain in 5 protocolli distinti che si intrecciano nel consenso della relay-chain.
1. Collation (Raccolta)
2. Backing
3. Availability (Disponibilità)
4. Approval Checking (Controllo dell'approvazione)
5. Disputes (Contestazioni)
Collation (Raccolta) è il processo con cui vengono creati i blocchi di parachain. I Collators costruiscono un blocco di parachain e lo inviano ai validators.
Il backing è il processo con cui i blocchi di parachain vengono inizialmente controllati da un piccolo gruppo di validatori della relay chain e registrati su di essa. Il principale effetto secondario del backing è che richiede ai validatori di mettersi in gioco se i protocolli successivi falliscono.
Availability è il processo con cui i validatori di backup distribuiscono pezzi di dati necessari per verificare il blocco di parachain e assicurano che sia disponibile per la verifica successiva.
Approval Checking è il processo con cui i validatori casuali recuperano i dati ed eseguono il blocco di parachain. Essi approvano o avviano una disputa in base alla validità del blocco di parachain.
Disputes sono il processo attraverso il quale le opinioni contrastanti dei validatori su un blocco di parachain vengono risolte e i blocchi di parachain difettosi vengono ignorati e i trasgressori puniti. Le controversie esistono solo come misura di sicurezza e non ci si aspetta che vengano attivate spesso.
Si noti che è probabile che i validatori siano impegnati in ciascuno di questi protocolli allo stesso tempo, e spesso in istanze multiple. Per esempio, un validatore potrebbe essere impegnato nel voto di approvazione per un blocco di parachain che si trova più avanti nella pipeline, mentre partecipa al sostegno per un blocco più recente e alle dispute per un blocco ancora più vecchio.
Questo parallelismo interno riflette anche l'architettura dell'implementazione: ognuno di questi protocolli è implementato come sottosistema indipendente e tutti i sottosistemi funzionano in parallelo. Ogni nodo fa sempre un po' di tutto.
Invio di blocchi e crescita delle parachain
Questa sezione illustra come le parachain crescono di pari passo con la relay chain.
L'inclusione di un potenziale blocco di parachain in una parachain richiede due fasi. Il primo è che il blocco di parachain sia referenziato da un blocco di relay-chain insieme alle attestazioni sulla sua validità. Il passo successivo è che i dati corrispondenti necessari per verificare il blocco di parachain siano riconosciuti come disponibili in un successivo blocco di relay-chain.
Poiché la relay chain può avere biforcazioni a breve termine, anche ogni parachain può avere biforcazioni a breve termine. Se ci sono due blocchi di relay-chain A e B in competizione a una data altezza e A contiene il blocco di parachain P e B contiene il blocco di parachain P', allora anche questo costituisce una biforcazione nella parachain.
Per gli scopi di questo post, considereremo una versione semplificata la state machine (macchina a stati) della relay chain di Polkadot. Come promemoria, ogni blocco di un ramo della relay chain rappresenta una transizione dallo stato precedente a quello successivo.

Il lavoro off-chain che i nodi svolgono per far crescere le parachain riguardano il confronto, il backup e la disponibilità.
I nodi monitorano gli ultimi blocchi della relay chain per determinare il lavoro da svolgere.
Un confronto consiste in una testa di parachain e in una PoV o prova di validità, ovvero tutti i dati necessari per verificare la transizione dalla testa della parachain precedente a quella attuale. Solo le teste si spostano sulla chain, ma le PoV devono essere disponibili. Per garantire la disponibilità dei PoV, utilizziamo la codifica di cancellazione: i dati sono suddivisi in pezzi chiamati chunk, uno per ogni validatore, e qualsiasi sottoinsieme sufficientemente grande di chunk può recuperare i dati completi. Questo fornisce una protezione contro i nodi che vanno offline o che mentono sul fatto di avere la loro parte di dati.
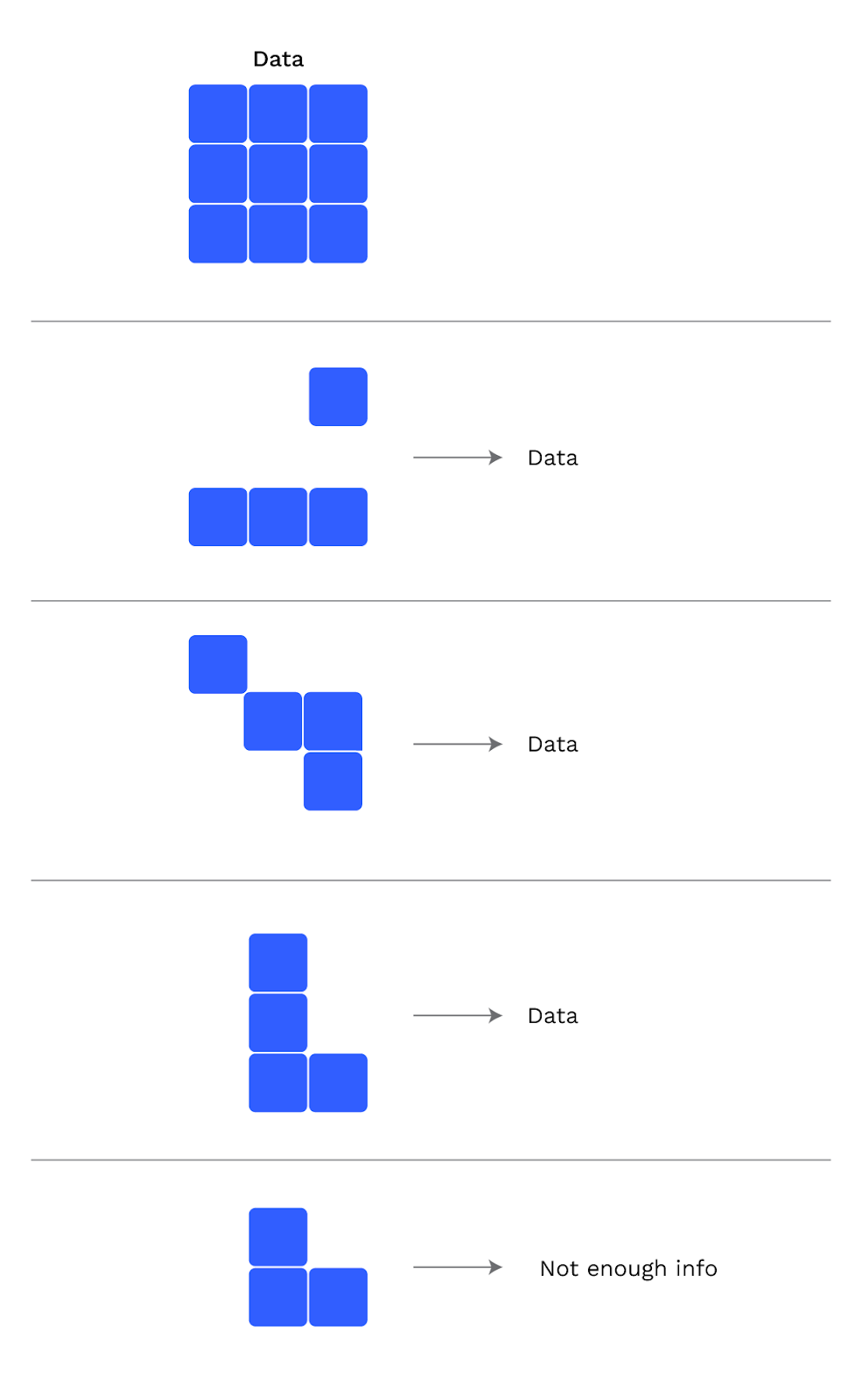
In questo esempio, i dati sono divisi in 9 parti e qualsiasi sottoinsieme di 4 o più grande può recuperare i dati completi.
Quando un validatore osserva che un core disponibile è vuoto e che la parachain programmata su quel core è una a cui il nodo è assegnato, cercherà di raccogliere una collezione da un collator e parteciperà al processo di backing. I nuovi blocchi potenziali di parachain, insieme alle loro attestazioni da parte dei validatori, vengono propagati attraverso un sistema di gossip. Ciò significa che ogni nodo ben connesso è a conoscenza di ogni prossimo potenziale blocco di parachain. L'autore del prossimo blocco di relay-chain monitora lo stato della rete e seleziona una serie di nuovi blocchi di parachain da supportare nel blocco di relay-chain che ha creato.
Ecco un diagramma di flusso che descrive approssimativamente la logica che i validatori eseguono per il processo di backup. Eseguono questa logica ogni volta che il core disponibile per la parachain è vuoto.

Questo diagramma mostra come i validatori ottengano blocchi di parachain freschi dai collators e collaborino con altri validatori per ottenere un supporto sufficiente dai validatori assegnati. I validatori che non sono assegnati alla parachain ascoltano comunque gli attestati, perché il validatore che finisce per essere l'autore del blocco di relay-chain deve raggruppare i blocchi di parachain certificati per diverse parachain e inserirli nel blocco di relay-chain.
Una volta che un blocco di parachain è supportato nella chain (cioè la sua intestazione è apparsa in un blocco di relay-chain insieme agli attestati dei validatori selezionati e ha superato vari controlli di correttezza), inizia a occupare il core disponibile.
Quando un validatore osserva che un core disponibile è occupato, tenta di recuperare il proprio chunk del PoV codificato a memoria di errore se non fa parte del gruppo di validatori che ha inizialmente certificato il blocco. In caso contrario, il validatore è responsabile della distribuzione dei chunk ai validatori corrispondenti.
Distribuzione della disponibilità: i validatori non backing richiedono i loro blocchi ai validatori backing. Alcuni dei validatori non di supporto potrebbero non essere in grado di connettersi direttamente, ma va bene così, purché ce ne siano abbastanza.

I validatori richiedono i loro pezzi di dati ai validatori di supporto, che sono tenuti a distribuirli.
Ogni validatore firma le dichiarazioni relative ai blocchi di parachain per i quali ha i suoi chunks e le diffonde. L'autore del blocco di relay-chain include tali dichiarazioni nella relay chain. Una volta che più di 2/3 dei validatori hanno indicato di avere il proprio chunk per il blocco di parachain che occupa un core, il blocco di parachain è considerato disponibile e viene ufficialmente incluso come parte della parachain e il core viene reso nuovamente libero.
Se la disponibilità non viene raggiunta entro un determainer numero di blocchi, il nucleo viene reso libero, essendo stato considerato fuori tempo massimo, e il blocco di parachain che lo occupa viene abbandonato.
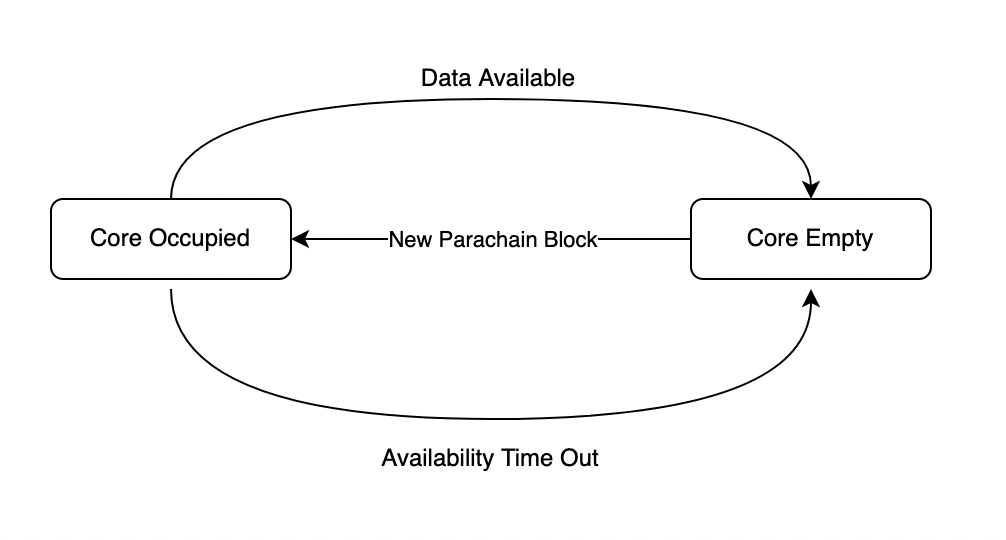
Logica del core disponibile come riepilogo
In sintesi, i protocolli di supporto e disponibilità assicurano che, quando un blocco di parachain è stato incluso, sia stato attestato da una piccola minoranza di validatori e che la disponibilità del PoV necessario per verificare il blocco di parachain sia stata attestata da almeno 2/3 dei validatori. In altre parole, l'appoggio e la disponibilità servono a mettere in gioco la persona e a imporre la responsabilità. Nelle prossime sezioni si parlerà di come Polkadot assicura che nessun blocco di parachain venga finalizzato senza essere stato controllato più a fondo.
Controllo di approvazione e finalizzazione
Il controllo di approvazione è un meccanismo con cui i validatori si auto-selezionano casualmente per controllare i blocchi di parachain disponibili e comunicano l'intenzione e i risultati dei loro controlli al resto della rete.
Per ora, lasciamo il processo effettivo di controllo dell'approvazione come una scatola nera. Inizieremo dando qualche informazione di base su ciò che vogliamo che questo protocollo faccia, in modo che sia chiaro in seguito il motivo per cui funziona in questo modo.
Come abbiamo già stabilito, ogni nodo validatore partecipa a GRANDPA, il gadget di finalizzazione. GRANDPA procede a turni, e possiamo vedere una versione troppo semplificata del lavoro che ogni validatore svolge in ogni turno GRANDPA come la ripetizione di questi passaggi:
-
Inizio del prossimo turno
-
Scegliere un blocco target di finalizzazione: il miglior blocco che vorremmo fosse finalizzato.
-
Votare l'obiettivo di finalizzazione
-
Attendere i voti degli altri validatori
-
Trovare il blocco più comune che appare in almeno 2/3 delle catene votate dai validatori.
-
Finalizzare quel blocco
-
Il round termina
L'unica flessibilità che un validatore ha in questo processo è nella fase 2: la scelta del blocco da votare come obiettivo di finalizzazione. Questa scelta è nota come regola di voto. Nel GRANDPA di base, ogni validatore sceglie semplicemente il ramo più lungo della relay chain di cui è a conoscenza e presenta la testa di quella chain come voto. Tuttavia, per il consenso parachain introduciamo una nuova regola di voto.
La regola di voto GRANDPA per il controllo dell'approvazione dice che ogni validatore deve:
1. Scegliere il ramo più lungo della relay chain.
2. Trovare il blocco B più alto della chain in modo che ogni blocco tra il blocco finalizzato corrente e fino a B attivi l'inclusione solo per i blocchi di parachain che il validatore ha osservato essere stati approvati da un numero sufficiente di validatori.
Vediamo come funziona. Ricordiamo che l'obiettivo principale è che la rete finalizzi solo blocchi di parachain che siano effettivamente validi e che ogni validatore faccia il minor lavoro possibile, in modo che la rete possa scalare. Quindi, in parti:
-
Trovare il blocco B più alto nella chain: Vogliamo che ogni nodo voti il blocco più alto possibile che soddisfi gli altri criteri in modo che la finalizzazione avanzi il più velocemente possibile.
-
In modo tale che ogni blocco tra il blocco finalizzato corrente e fino a B: la regola di voto prevede che i validatori votino su una chain che contiene solo blocchi di parachain buoni. In GRANDPA, un voto su un blocco conta come un voto su tutti i suoi antenati, quindi anche se il blocco 100 contiene solo blocchi di parachain buoni, i blocchi 99 e 98 potrebbero non esserlo. Pertanto, la regola di voto deve trovare la più alta chain contigua di blocchi di relay-chain che superi gli altri criteri.
-
**Il criterio di voto è quello che fa scattare l'inclusione solo per i blocchi di parachain:**Facendo riferimento alla sezione sull'estensione della parachain, si intende che i blocchi di parachain sono diventati disponibili in virtù delle attestazioni di disponibilità nel blocco di relay-chain e che i blocchi di parachain sono stati aggiunti alla parachain. I blocchi di parachain che non sono ancora disponibili non contano ancora come parte della parachain.
-
Che il validatore ha osservato essere stato approvato da un numero sufficiente di validatori: Questo si riferisce al meccanismo di controllo dell'approvazione che descriveremo più avanti, che è un modo per i validatori di avere un'alta fiducia nella bontà di un blocco di parachain senza necessariamente verificarlo loro stessi, affidandosi ai controlli degli altri.
Di seguito sono riportati 3 esempi di come viene applicata la regola di voto per selezionare i blocchi da votare per la finalizzazione.
Nel primo esempio, viene mostrata la proprietà di contiguità e il fatto che si sceglie un antenato della chain migliore.
Nel secondo esempio, si vota il blocco finalizzato perché nessuna delle due catene è finalizzabile.
Nel terzo esempio, l'intera chain migliore è finalizzabile, quindi scegliamo di votare su quella.
Arrivare al sì: la programmazione e la macchina a stati di approvazione

Il controllo dell'approvazione rallenta un po' la finalizzazione, ma solo un po'. Le parachain possono avere un tempo di esecuzione di circa 3 secondi, e ci vuole circa 1 secondo per recuperare i dati e qualche secondo in più per il gossip dei messaggi. Nel caso ottimistico, questo significa che aggiunge circa 5 secondi in più alla finalità. E questa è una vera finalità, con tutto il peso di Polkadot alle spalle.
Approfondiamo quindi il processo di verifica dell'approvazione e cosa fanno effettivamente i nodi per avere un'idea di quali blocchi di parachain sono buoni e sono stati verificati da un numero sufficiente di validatori.
Controllo delle proprietà e della sicurezza
Il controllo dell'approvazione è un sottoprotocollo che i validatori eseguono per ogni singolo blocco di parachain.
Ogni nodo validatore esegue un processo di controllo dell'approvazione per ogni blocco di parachain in ogni blocco di relay-chain. Questo processo ha alcune proprietà:
-
Il processo, su un particolare nodo, produce un risultato "buono" o si blocca.
-
Se il blocco di parachain è valido (cioè supera i controlli), alla fine darà un risultato "buono" sui nodi onesti.
-
Se il blocco di parachain non è valido, allora darà l'esito "buono" solo su nodi onesti con bassa probabilità.
Si noti che la "bassa probabilità" nel caso non valido è qualcosa come 1 su diversi miliardi, a seconda di variabili come il numero di validatori e il numero di controllori minimi. Questa non è la versione crittografica della bassa probabilità, ma è adatta alla crittoeconomia.
L'argomento della sicurezza di Polkadot si basa sulla Rovina del Giocatore. Se è vero che un attaccante che può fare miliardi di tentativi per forzare il processo avrebbe successo, noi combiniamo questo processo con un sistema di slashing che assicura che ogni tentativo fallito sia accompagnato da uno slash dell'intera posta in gioco dei validatori attaccanti. Polkadot è una rete di proof-of-stake e, al momento in cui scriviamo, ogni validatore è supportato da circa 2 milioni di DOT di valore. Molto probabilmente, ogni tentativo fallito provocherebbe il taglio di 10 o 20 validatori. Ma anche se venisse tagliato un solo validatore, è comunque evidente che i fondi di un attaccante si esaurirebbero rapidamente prima di un probabile successo.
Questo risultato si ottiene con alcune proprietà del controllo di approvazione:
-
Le assegnazioni dei validatori per il controllo di un blocco di parachain sono segrete finché non vengono rivelate da loro stessi.
-
Le assegnazioni dei validatori sono generate in modo deterministico.
-
I validatori trasmettono l'intenzione di controllare un blocco di parachain prima di recuperare i dati necessari per eseguire i controlli.
-
Quando i validatori trasmettono l'intenzione di controllare un blocco di parachain e poi scompaiono, questo fa sì che altri validatori onesti inizino a controllare.
La proprietà 1 garantisce che un aggressore non sappia a chi rivolgersi per impedire la verifica di un blocco.
La proprietà 2 garantisce che, anche se l'attaccante ha avuto un "sorteggio" fortunato e dispone di un numero sufficiente di nodi maligni per convincere i nodi onesti che qualcosa è stato controllato, è molto probabile che ci siano nodi onesti che effettueranno i controlli insieme a lui e che questi nodi onesti daranno l'allarme.
La proprietà 3 garantisce che i nodi onesti non si rivelino accidentalmente come verificatori, richiedendo dati a nodi maligni e venendo quindi messi offline dall'avversario senza che nessuno se ne accorga.
La proprietà 4 garantisce che i nodi che sembrano essere stati oggetto di DoS vengano sostituiti da altri nodi. Il controllo dell'approvazione è concepito come l'idra: se si taglia una testa, ne compaiono altre due.
Le prossime sezioni approfondiranno il funzionamento del controllo di approvazione.
Cosa verificano i validatori?
L'obiettivo dei validatori è quello di decidere se i validatori di supporto sono stati coinvolti in un comportamento scorretto. Questo richiede 3 fasi:
-
Scaricare i dati PoV per controllare il blocco. Questo viene fatto prendendo 1/3 dei chunk e combinandoli per formare i dati completi.
-
Assicurarsi che i dati PoV corrispondano a una transizione di stato parachain valida.
-
Assicurarsi che tutte le uscite previste dall'intestazione del blocco di parachain corrispondano effettivamente alle uscite dell'esecuzione del blocco di parachain.
Il recupero della disponibilità non dovrebbe mai fallire nell'ipotesi che >2/3 dei nodi siano onesti e si siano impegnati ad avere la loro porzione di dati. Questo è il motivo per cui il controllo dell'approvazione viene effettuato solo per i blocchi di parachain disponibili.
Tuttavia, le fasi (2) e (3) possono fallire entrambe. Quando il passo (2) fallisce, indica che la transizione di stato in sé è spazzatura. Quando il passo (3) fallisce, significa che la transizione di stato è riuscita, ma le informazioni registrate nella relay chain sulle sue uscite erano false.
Un caso importante da notare nel passo (3) è che l'intestazione del blocco di parachain contiene un impegno per tutti i pezzi della codifica a cancellazione. I validatori eseguono un controllo supplementare dopo aver recuperato i dati del PoV, che consiste nel riconvertire il PoV nella sua forma codificata a cancellazione e assicurarsi che l'impegno nell'intestazione corrisponda a tutti i blocchi. Se non c'è corrispondenza, si evita un tipo di attacco in cui un aggressore può scegliere selettivamente quali validatori possono recuperare i dati. Il modo in cui funziona l'attacco è il seguente: un attaccante divide i dati in pezzi e sostituisce tutti i pezzi tranne 1/3 con spazzatura. Distribuisce 1 pezzo valido a un validatore onesto e dà a un altro 1/3 dei validatori dati spazzatura. Il terzo malintenzionato dei validatori trattiene il resto dei pezzi con dati validi. Ciò significa che ci sono abbastanza validatori (2/3 + 1) per considerare i dati disponibili, ma se i validatori maligni si rifiutano di rispondere alle richieste sul loro 1/3 di pezzi validi, allora sarà disponibile solo spazzatura. La verifica che la ricodifica dei dati corrisponda effettivamente all'impegno sconfigge l'attacco.
Se i passaggi (2) o (3) falliscono, il verificatore solleverà una controversia e farà passare il blocco a tutti i validatori per eseguire gli stessi controlli. Torneremo sulle controversie più avanti per discutere esattamente cosa significa.
Quando controllare
Uno dei punti chiave per comprendere il sistema di controllo dell'approvazione è che a ogni validatore è assegnato il compito di controllare ogni blocco di parachain, ma è una questione di tempi di controllo. Se un validatore vede un blocco di parachain approvato prima che sia il suo turno di controllo, semplicemente non lo controlla e passa oltre.
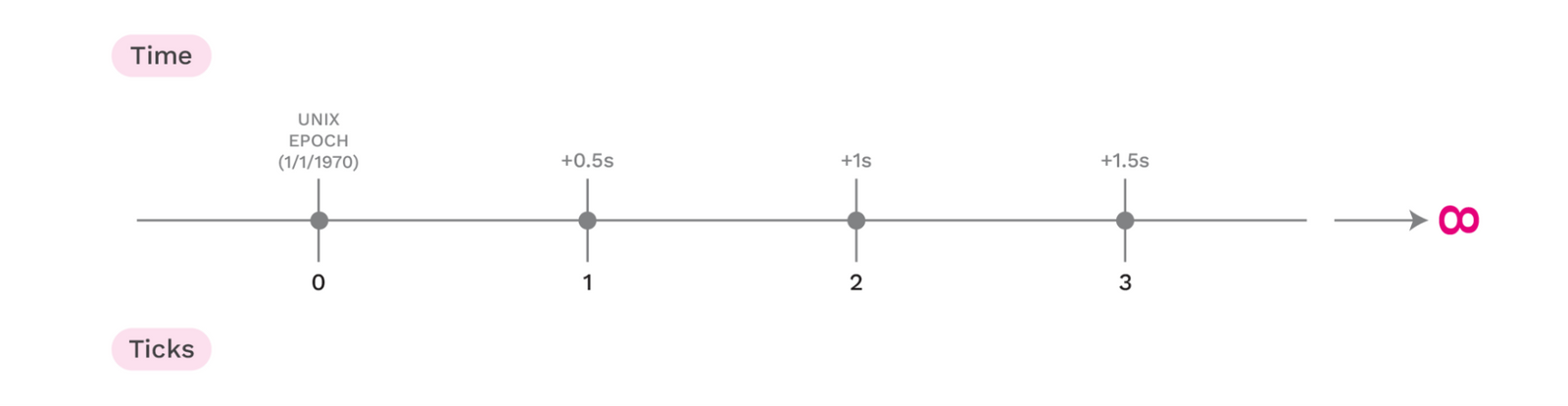
Il tempo è diviso in intervalli discreti di 0,5 secondi a partire dall'Unix Epoch. La scelta di 0,5 secondi si basa sul tempo previsto per la propagazione di piccoli messaggi attraverso la rete di gossip.
Il tempo in cui un validatore deve controllare un blocco di parachain è espresso in una tranche di ritardo, che è relativa al blocco di parachain. Le tranche di ritardo vanno da 0 a MAX_TRANCHES e corrispondono al numero di tick dopo che un nodo viene a conoscenza della disponibilità del blocco di parachain. I nodi hanno visioni leggermente diverse su quale sia il tick a cui corrisponde la tranche 0. MAX_TRANCHES è un parametro del protocollo che determina il tempo necessario per controllare ogni blocco di parachain. Impostandolo troppo piccolo, si rischia di selezionare un numero di verificatori superiore a quello necessario, con conseguente spreco di energie. Impostarlo troppo grande significa che ci vuole troppo tempo per controllare i blocchi di parachain. Per riferimento, questo parametro è impostato a 89 su Polkadot e Kusama al momento della scrittura.
I tick sono una misura discreta del tempo, basata su incrementi di mezzo secondo a partire dall'Unix Epoch.
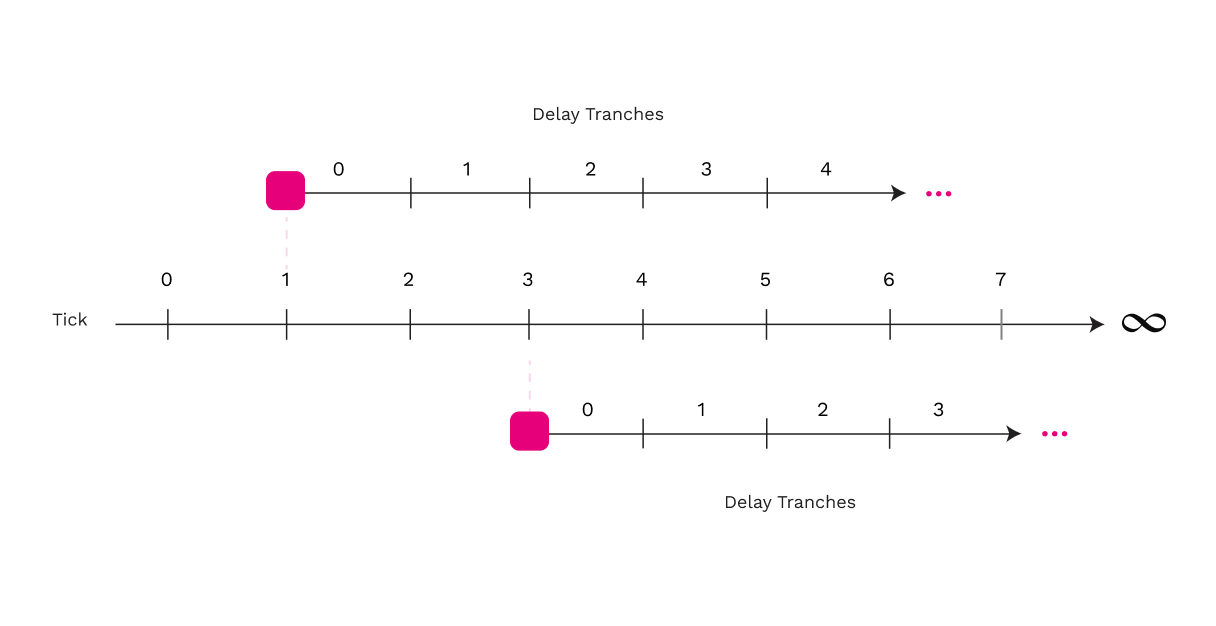
La tranche 0 è speciale, in quanto il numero previsto di verificatori nella tranche 0 è progettato per essere approssimativamente uguale a MIN_CHECKERS, che è un parametro del protocollo che specifica la quantità minima di controlli richiesti prima che un blocco di parachain possa essere considerato approvato dalla procedura di controllo di approvazione.
I validatori che facevano parte del gruppo di supporto del blocco di parachain non possono partecipare al controllo di approvazione perché i loro controlli sarebbero ridondanti. Tutti gli altri validatori eseguono localmente un calcolo VRF per determinare in quale tranche di ritardo sono destinati a controllare.
Assegnazioni, approvazioni e no-show
Esistono due tipi di messaggi che i validatori inviano nel controllo dell'approvazione: Assegnazioni e Approvazioni. Gli assegnamenti sono usati per comunicare l'intenzione e l'idoneità a controllare un blocco di parachain, mentre un messaggio di approvazione indica che un blocco di parachain ha superato tutti i controlli.
Ogni validatore genera immediatamente un'assegnazione per verificare il blocco di parachain utilizzando come input un VRF, l'ID di parachain e la credenziale BABE del blocco di relay-chain. I validatori mantengono il loro incarico privato fino a quando non è necessario. Ogni assegnazione è associata in modo univoco e deterministico a una tranche di ritardo, che indica la tranche di ritardo in cui il validatore è assegnato alla verifica del blocco di parachain.
Il VRF è importante perché significa che l'assegnazione è verificabile dai destinatari e che il validatore assegnato non ha alcuna influenza sulla tranche di ritardo a cui è assegnato. I validatori hanno una certa influenza indiretta attraverso attacchi più sofisticati che comportano la biforcazione deliberata della relay chain quando la casualità BABE è favorevole, ma questo lo lascerò per un altro articolo.
Un'approvazione è un semplice messaggio, firmato dal validatore che lo ha emesso, che indica che un blocco di parachain ha superato i controlli.
Quando un validatore inizia a controllare un blocco di parachain, la prima cosa che fa è spettegolare la sua assegnazione agli altri validatori. Questo informa gli altri validatori di attendere il messaggio di approvazione corrispondente. Una volta termainer il controllo, il validatore emette un messaggio di approvazione. Se il messaggio di approvazione non arriva entro NO_SHOW_DURATION, gli altri nodi considerano il validatore iniziale come un no-show. Il no-show indica che un avversario ha osservato l'intenzione del validatore di verificare il blocco di parachain e ha tentato di metterlo a tacere. NO_SHOW_DURATION è un parametro del protocollo che attualmente è impostato a 12 secondi su Polkadot.
Ecco un diagramma che mostra 3 casi: un no-show, un incarico eseguito e un adempimento tardivo. L'ultimo caso è particolarmente importante, perché mostra come i validatori possano "tornare dalla morte" e far valere la loro approvazione anche dopo essere stati considerati non presenti.
 Arrivare al sì: la programmazione e la macchina a stati di approvazione
Arrivare al sì: la programmazione e la macchina a stati di approvazione
Quest'ultima sezione sul protocollo di controllo dell'approvazione descriverà in dettaglio la macchina a stati per l'approvazione di un blocco di parachain.
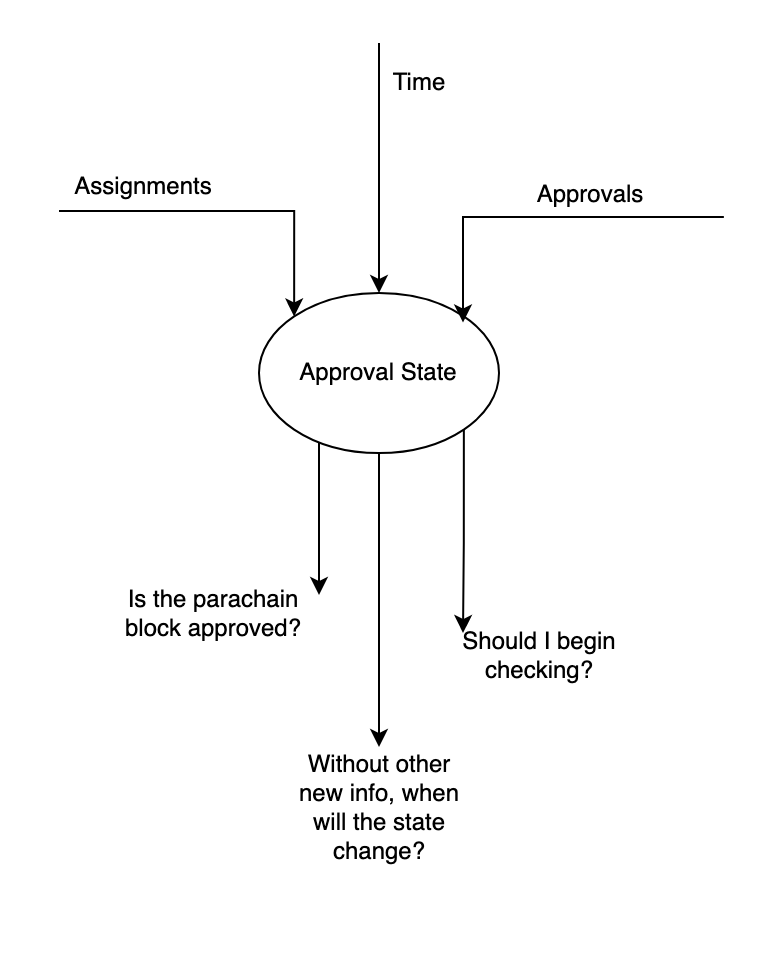
Ogni nodo validatore mantiene uno stato di approvazione per ogni blocco di parachain inserito (disponibile). Le versioni dei validatori dello stato possono differire a causa della tempistica e dell'asincronia della rete. Lo stato ci permette di rispondere a domande come:
-
Il blocco di parachain è approvato?
-
È rilevante un'assegnazione con la tranche T?
-
In assenza di altri input, qual è il momento successivo in cui le risposte alle domande (1) o (2) potrebbero essere cambiate?
Lo stato di approvazione può essere aggiornato in 3 modi: ricevendo un nuovo incarico, ricevendo una nuova approvazione o avanzando nel tempo.
I validatori eseguono la macchina a stati finché la risposta alla domanda (1) è "sì". Dopo ogni input, usano la domanda (2) per determinare se devono iniziare a controllare il blocco di parachain, verificando se il loro incarico è rilevante. La domanda (3) è necessaria solo a fini di ottimizzazione: i nodi eseguono tipicamente migliaia di queste macchine a stati in parallelo (una per ogni blocco di parachain non finalizzato) ed è inefficiente interrogarle tutte a ogni tick.
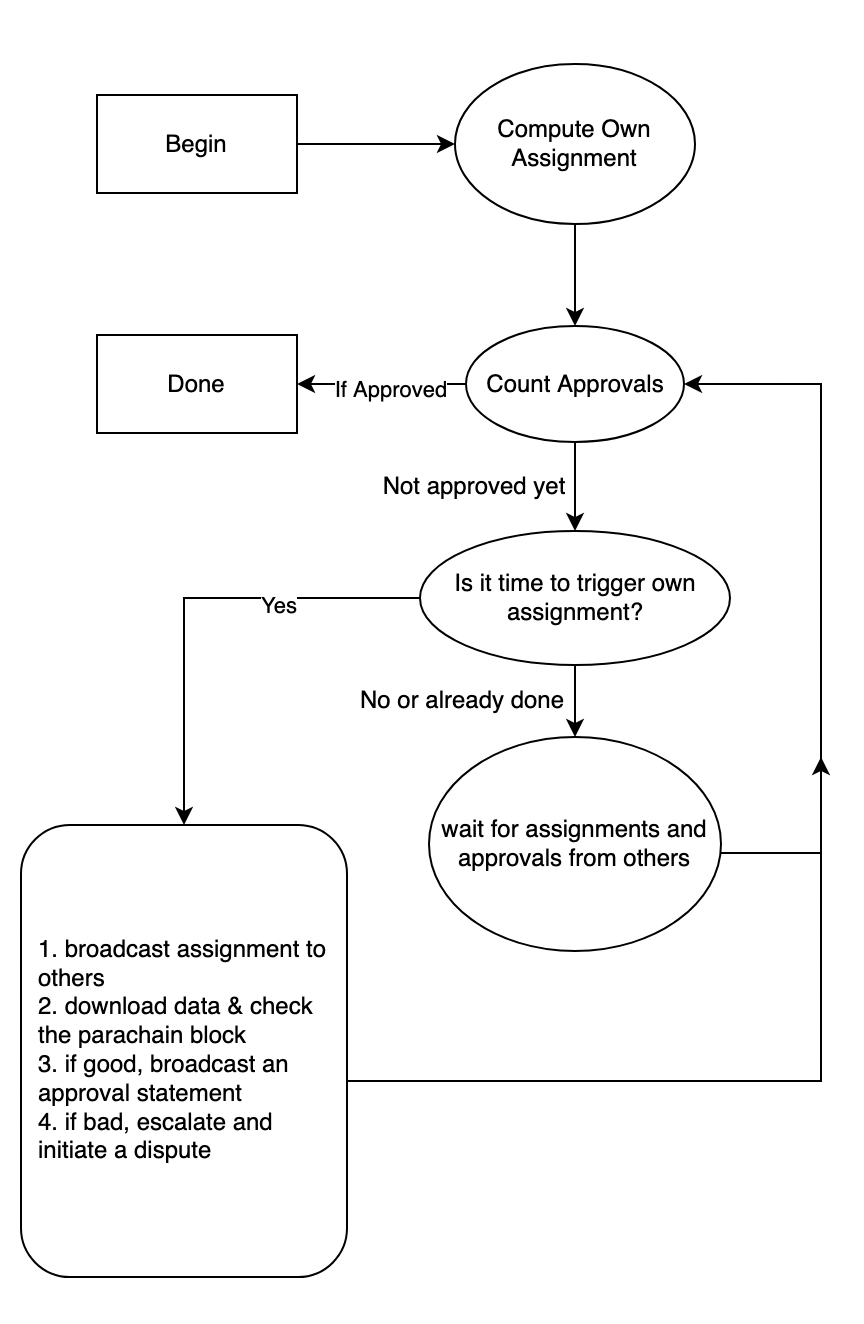
Questa è la logica che ogni validatore esegue finché i blocchi di parachain non vengono approvati
Lo stato contiene in realtà due parti:
-
Tutte le assegnazioni ricevute, ordinate per tranche e annotate con il tick in cui sono state osservate per la prima volta.
-
Tutte le approvazioni ricevute.
-
Un validatore non include il proprio incarico nello stato finché non inizia la verifica. Quando produce un'approvazione, il validatore la include nello stato.
Ecco una rappresentazione visiva dello stato; è un oggetto neutro che può rispondere a domande basate su quali assegnazioni sono arrivate, quanto tempo è passato e quali approvazioni sono arrivate.
*
Un incarico si trova in uno dei 3 stati:
-
In attesa: L'incarico non ha un'approvazione corrispondente, ma è stato assegnato di recente.
-
Soddisfatto: L'incarico ha un'approvazione corrispondente.
-
Non presentato: L'incarico non ha un'approvazione corrispondente e non è stato assegnato di recente.
Gli incarichi non presentati devono essere ricoperti da almeno una tranche non vuota. Cioè, ogni no-show deve essere garantito da almeno un incarico, ma in teoria da più di uno (in base alla parametrizzazione).
La determinazione del numero di tranche da prendere si effettua con la seguente procedura:
-
Prendere le tranche, a partire dalla tranche 0, finché non contengono almeno assegnazioni MIN_CHECKERS.
-
Prendere le tranche non vuote, una per ogni no-show. Se ci sono altre no-show in quelle tranche non vuote, ripetere il passo 2.
-
Se tutte le assegnazioni di no-show sono soddisfatte, il blocco di parachain è approvato. In altre parole, se una qualsiasi assegnazione è ancora in sospeso, il blocco di parachain non è approvato.
Se in qualsiasi momento si esauriscono le tranche da prendere (il massimo è un parametro del protocollo), il blocco non viene approvato. Nella versione reale di questo protocollo, ci sono ulteriori vincoli per quanto riguarda il non prendere tranche che sono "nel futuro", nonché una deriva temporale basata su ogni iterazione del passo 2.
Questo diagramma di flusso mostra la logica che ogni validatore esegue per determinare se un blocco di parachain è approvato. È importante notare che questo si basa solo sulle assegnazioni e sulle approvazioni che il validatore ha effettivamente visto. Potrebbero esistere assegnazioni che cambiano il risultato della procedura di conteggio, ma se non sono state ricevute dal validatore che esegue la procedura non possono essere considerate.
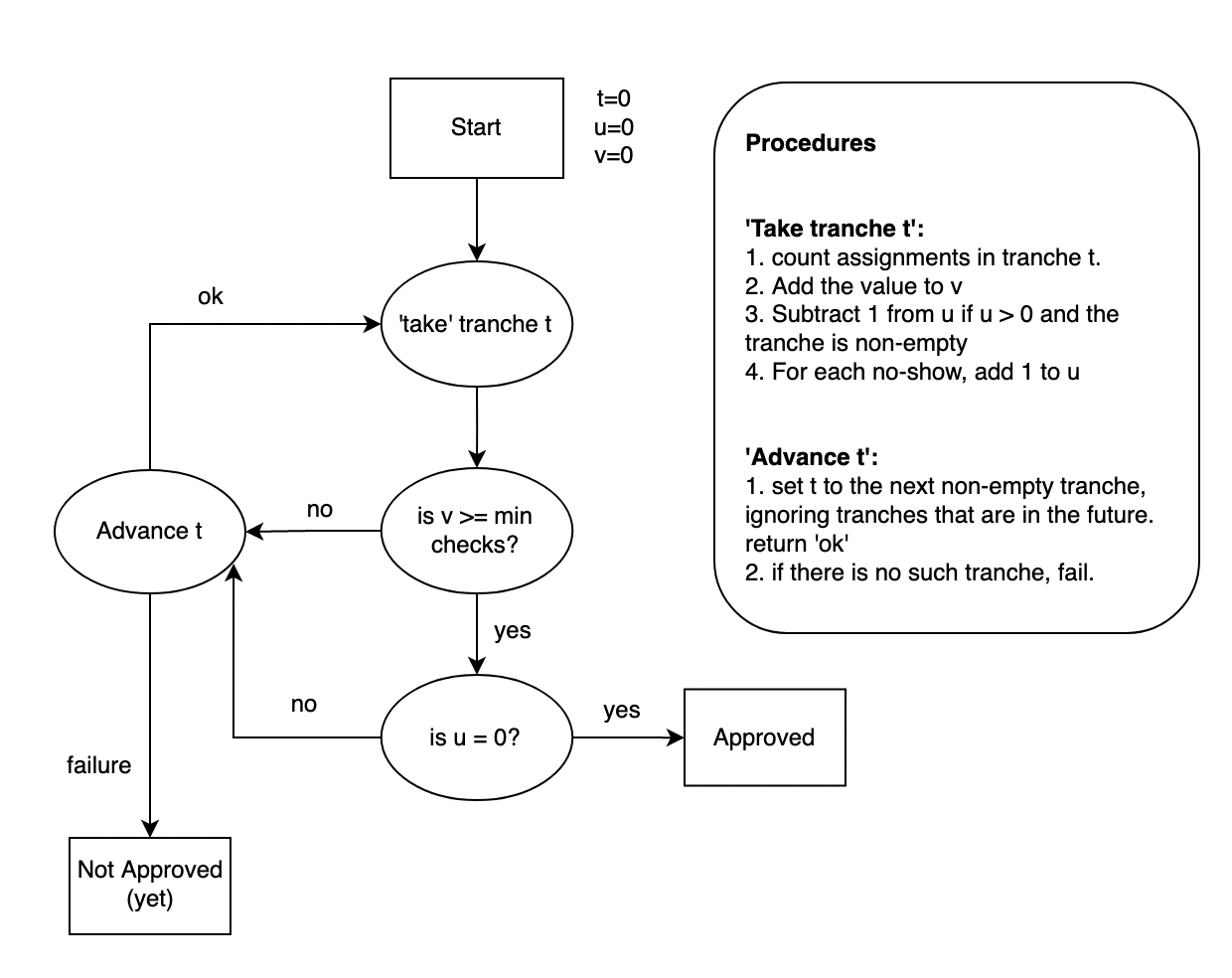
Come contare e interpretare le assegnazioni e le approvazioni ricevute
I punti chiave di questa procedura sono che le assegnazioni per le tranche successive non vengono conteggiate affatto se ci sono abbastanza assegnazioni in anticipo e che i nodi che scompaiono in circostanze misteriose vengono sostituiti.
Ecco 4 esempi di risultati della procedura di conteggio delle approvazioni:

Ogni volta che un validatore esegue questa procedura di conteggio delle approvazioni e scopre che sono necessarie altre assegnazioni, verifica se deve attivare la propria assegnazione e iniziare la verifica. Il validatore attiva la propria assegnazione se
-
Il validatore non ha già attivato la propria assegnazione.
-
La tranche dell'assegnazione è rilevante per lo stato: o fa parte di una tranche che lo stato già conteggia o la procedura di conteggio ha esaurito le tranche e l'assegnazione non è nel futuro.
In sintesi
Il protocollo di verifica dell'approvazione è il principale meccanismo di rilevamento delle frodi di Polkadot. Prima che qualcosa raggiunga questa fase, ci siamo assicurati che i dati necessari per il controllo siano disponibili. Questo meccanismo porta all'approvazione o all'escalation di ogni blocco di parachain ed è stato progettato in modo che un attaccante DoS che tenti di eliminare i validatori che controllano venga sostituito da un numero ancora maggiore di controllori. Il controllo di approvazione è l'idra. È progettato per mangiare gli attaccanti e sputarli all'altra estremità. Dove li manda è un sistema che chiamiamo dispute: Il Tribunale del Consenso di Polkadot.
Controversie: discutere per il denaro
Una controversia si verifica quando 2 o più validatori non sono d'accordo sulla validità di un blocco di parachain. Mentre la maggior parte del contenuto precedente di questo articolo si concentra sul percorso felice, cioè il caso in cui un blocco di parachain è effettivamente valido, le controversie riguardano il percorso di errore in cui un validatore rileva effettivamente che un blocco di parachain non valido è diventato disponibile.
Il processo di contestazione è relativamente semplice. È stato progettato per raggiungere i seguenti obiettivi:
-
Determinare se il blocco di parachain è buono o cattivo sottoponendolo al voto di tutti i validatori.
-
Se il blocco di parachain è cattivo, assicurarsi di non finalizzare o costruire su qualsiasi blocco di relay-chain che lo renda disponibile.
-
Assicurarsi che i perdenti della disputa siano puniti di conseguenza.
In primo luogo, le dispute servono a soddisfare uno degli obiettivi di livello superiore di Polkadot: assicurarsi che nulla di negativo venga finalizzato.
I validatori che partecipano a una disputa esprimono un voto nella categoria "a favore" o "contro". La partecipazione è automatica o dichiarata in modo esplicito.
La partecipazione è automatica grazie al controllo del supporto e dell'approvazione. Quando un validatore ha rilasciato un'attestazione di supporto o un messaggio di approvazione per un blocco di parachain, conta automaticamente come se avesse partecipato alla categoria " a favore". In effetti, i validatori onesti tengono un registro di tutti i recenti messaggi di sostegno e di controllo dell'approvazione che hanno ricevuto, per poter presentare in seguito delle prove contro i loro colleghi.
La stragrande maggioranza dei validatori non è un partecipante automatico. Questi validatori partecipano esplicitamente, il che significa che firmano un voto per la categoria "a favore" o "contro". Lo fanno dopo aver fatto gli stessi controlli che fa un verificatore di approvazione, ovvero,
-
Scaricare i dati PoV.
-
Convalida della transizione di stato
-
Convalida degli impegni verso le uscite della transizione di stato
La partecipazione non è obbligatoria, ma una disputa non può essere risolta finché almeno 2/3 dei validatori non hanno espresso un voto a favore di una delle due parti. I validatori sono ricompensati per la partecipazione e sono premiati per essere dalla parte della maggioranza.

Ci sono penalità di slashing per chi perde una disputa. Contestare un blocco di parachain che è effettivamente valido è solo una perdita di tempo e di larghezza di banda, quindi c'è una piccola penalità per questo. Presentare un blocco di parachain non valido è un attacco contro Polkadot, quindi la penalità è del 100%.
Controversie a distanza e locali
Le controversie sono principalmente un processo off-chain. Si verificano cioè a livello delle "catene" e non a livello della "chain". Tuttavia, i fork della relay chain che alla fine viene finalizzata dovrebbe contenere una registrazione della controversia. Questo perché lo slashing è un processo che avviene all'interno della chain.
Quando si verifica una disputa, tutti i voti vengono registrati in ogni fork della chain per attivare lo slashing e creare una registrazione permanente della disputa.
Una controversia remota, rispetto a un fork della relay chain, è quella che fa riferimento a un blocco di parachain non incluso in questo fork della relay chain.
Una controversia locale, rispetto a un fork della relay chain, è quella che fa riferimento a un blocco di parachain che è stato incluso in questo fork della relay chain.
Questa decisione è stata presa perché ci informa su quali fork della relay chain devono essere abbandonati. Qualsiasi biforcazione della relay chain che registra una disputa locale che si conclude contro il blocco di parachain deve essere evitata e non conservata dai validatori onesti. In altre parole, i validatori onesti che osservano che un blocco di parachain è cattivo inizieranno automaticamente un attacco al 51% contro i fork della relay chain che contengono il blocco di parachain cattivo.
Il risultato finale è che il fork finalizzato della relay chain non contiene blocchi di parachain che hanno perso dispute. Tuttavia, quando i validatori onesti costruiscono la nuova chain e omettono il blocco di parachain difettoso, riproducono la disputa sulla nuova biforcazione come disputa remota. La punizione viene conservata, ma gli effetti del crimine vengono cancellati dalla storia.
Questo diagramma mostra come un blocco di parachain contestato sia remoto o locale, a seconda del fork della relay chain che si sta osservando:

Controversie e regole di consenso
Come per il controllo dell'approvazione, le controversie comportano modifiche alle regole di partecipazione al consenso per i validatori onesti. Queste modifiche hanno due obiettivi principali
-
Evitare di finalizzare qualsiasi fork della relay chain che faccia riferimento a un blocco di parachain cattivo.
-
Evitare di costruire su qualsiasi fork della relay chain che faccia riferimento a un blocco di parachain cattivo.
Questi obiettivi corrispondono a cambiamenti di comportamento all'interno di GRANDPA e BABE, rispettivamente.
La regola di voto GRANDPA è una modifica della regola di voto GRANDPA che controlla l'approvazione. Essa afferma che:
-
Scegliere un blocco in base alla regola di voto di verifica dell'approvazione.
-
Trovare il blocco B più alto nella chain, in modo che tutti i blocchi dall'ultimo blocco finalizzato fino a B attivino l'inclusione solo per i blocchi di parachain che non hanno controversie in corso o che hanno perso controversie.
L'impostazione è simile a quella della regola di voto per il controllo dell'approvazione, ma vediamo le parti più importanti: i validatori ignorano i blocchi di relay-chain e attivano l'inclusione per i blocchi di parachain:
-
che non hanno dispute in corso: Questo indica ai validatori di evitare di finalizzare i blocchi di parachain che sono in contesa finché non hanno partecipato abbastanza validatori. In altre parole, "meglio prevenire che curare".
-
che hanno perso delle dispute: Se un validatore vede che i 2/3 dei pareri sono contrari a un blocco di parachain, non voterà mai per finalizzare un blocco di relay-chain che attiva l'inclusione per quel blocco di parachain.
In questo diagramma vengono mostrati alcuni esempi di applicazione della regola di voto "dispute GRANDPA" su una chain:

-
I blocchi di relay-chain sono considerati vitali se sono finalizzati o se il loro blocco padre è vitale e ogni blocco di parachain per cui il blocco di relay-chain attiva l'inclusione è indiscusso o ha vinto una disputa.
-
Un blocco di relay-chain è una pagina valida se non ha figli validi.
-
I validatori devono basarsi sulla pagina valida con il peso più alto di cui sono a conoscenza.
L'implicazione della regola di selezione della chain BABE è che i validatori onesti abbandoneranno le biforcazioni della relay chain che attivano l'inclusione per qualsiasi blocco di parachain che risulti non valido, anche se ciò significa costruire temporaneamente su una chain più corta.
Il diagramma seguente mostra esempi di come la regola di selezione della chain BABE richieda ai validatori di abbandonare e smettere di costruire su catene che contengono blocchi di parachain che hanno perso le dispute. In questo modo attaccano effettivamente il 51% del ramo cattivo della relay chain.

In pratica, si tratta di un rollback breve e automatico della relay chain. Ecco un esempio:
-
Nel blocco 1a viene incluso un blocco di parachain P.
-
Quando viene costruito il blocco 3a, il blocco di parachain P è stato contestato e ritenuto non valido.
-
I validatori onesti iniziano a ignorare il blocco 1a e tutti i suoi figli. Costruiscono invece una nuova chain partendo da un blocco alternativo 1b che non include il blocco di parachain P non valido.
-
Questi validatori onesti inviano i messaggi di disputa relativi al blocco di parachain P alla nuova biforcazione della relay chain, il che assicura che i sostenitori di P siano tagliati. Una volta costruita la 4b, essa supera la chain originale e la 1b viene finalizzata.
Il rollback è possibile perché i validatori onesti non finalizzano 1a finché non viene approvato, e il processo di approvazione è ciò che ha sollevato la controversia. Una volta che P viene contestato, i validatori mettono in attesa la finalizzazione di 1a. Quando P perde la controversia, i validatori si rifiutano di finalizzare l'1a in qualsiasi circostanza.

In sintesi, la logica delle dispute è un mezzo per garantire che il comportamento scorretto rilevato venga punito in modo adeguato e che la relay chain si riorganizzi per evitare completamente il blocco di relay-chain cattivo. Le dispute e le regole di selezione della chain associate sono gli elementi principali che differenziano Polkadot da un normale rollup ottimistico. I rollup ottimistici operano in cima a una chain sulla quale non hanno alcuna influenza sulla finalizzazione o sulla scelta del fork, il che significa che devono essere estremamente conservativi riguardo al rischio di finalizzare qualsiasi blocco che non va bene e quindi impongono lunghi periodi di frode e durate di ritiro (giorni o settimane).
In Polkadot, il protocollo delle controversie e le regole di selezione della chain fanno sì che la finalizzazione sia semplicemente ritardata di qualche secondo quando una controversia è in corso e la chain può costruirsi attorno al blocco difettoso. La finalità è comunque veloce e sicura.
Tutti insieme
Questo post è stato un'approfondita introduzione al consenso della blockchain e a come abbiamo applicato questi concetti per costruire Polkadot nel suo complesso. Gran parte della nostra metodologia di progettazione è stata incentrata sull'assicurare che le cose funzionino rapidamente quando le condizioni della rete sono buone, ma correttamente quando le condizioni della rete sono cattive. Per la maggior parte del tempo, non ci saranno validatori che attaccano. Le latenze di rete saranno basse e la larghezza di banda elevata. In queste condizioni, l'approvazione e l'esito finale possono avvenire in pochi secondi. Ma quando ci sono validatori che attaccano o le condizioni della rete sono scarse, la finalizzazione rallenterà di conseguenza e la relay chain ha il potere di riorganizzarsi intorno ai blocchi di parachain cattivi.
Abbiamo lavorato su questa serie di protocolli, in una forma o nell'altra, dall'estate del 2016. È incredibilmente gratificante vedere queste cose implementate e funzionanti live e su network altamente decentralizzati.
Il problema della scalabilità della blockchain è peggiorato da quando abbiamo intrapreso questo viaggio diversi anni fa. Abbiamo visto una serie di approcci, ma molti di essi mancano di sicurezza o di decentralizzazione. Polkadot, grazie ai suoi sistemi di backing, availability, approval checking e sistemi di dispute, è una soluzione pratica che offre scalabilità, decentralizzazione e sicurezza.
Sullo sviluppo dei protocolli
(Seguono opinioni personali)
La costruzione di software è una lotta costante tra ideali, pragmatismo, estetica e tempo. La realtà non corrisponde mai del tutto all'ideale. Niente è mai perfetto, ma le cose possono andare bene.
C'è uno scostamento tra la versione idealizzata di un protocollo e le implementazioni che alla fine vengono eseguite sui computer. È simile alla differenza tra un personaggio di un'opera teatrale e l'incarnazione di quel personaggio da parte di un attore. I server di tutto il mondo indosseranno il costume dei nostri validatori, ma non diventeranno mai i validatori del nostro protocollo, per quanto si sforzino.
Lo sviluppo del protocollo è una grande impresa. Richiede molto tempo, energia e concentrazione. Richiede la disponibilità a ignorare la stragrande maggioranza delle cose che accadono ai margini. Questi sacrifici sono archetipici: un'opera può essere creata solo offrendo tutto ciò che non è. Costruire qualcosa significa orientare i simboli in relazione gli uni agli altri. Soprattutto, costruire richiede la volontà di fallire. Come sviluppatori di protocolli, non abbiamo altra scelta che fallire. Ma nel farlo incontriamo l'assurdo e troviamo un significato.
I mass media di Internet incoraggiano messaggi di costruzione principalmente come mezzo per raggiungere un fine. Siamo incoraggiati a costruire come parte di qualcosa di più grande: affari, sistemi finanziari, movimenti sociali e dichiarazioni politiche. È importante fondare questi obiettivi sulla maestria artigianale e sulla semplice gioia di aver costruito qualcosa di non solo funzionale, ma intriso di cure ed eleganza. Lo sforzo di costruire ogni pezzo di un sistema per essere in linea con gli altri è fonte di orgoglio e vale la pena anche a costo di altre ricompense materiali.
Abbiamo costruito i protocolli qui descritti per oltre 5 anni e ho scelto di concludere questo post in questo modo per rispondere alla domanda che molti lettori si porranno: "Perché qualcuno dovrebbe spendere 5 anni per fare questo?". Questo è un messaggio per tutti i nuovi arrivati nello spazio crittografico. Questo è per tutti coloro che hanno cavalcato le onde dopo le impennate del 2020. Se cercate un rifugio dall'avidità e dalla mischia, esiste, ed è sempre stato qui.
